
stream
A wild speed-up from OpenAI Dev Day
7 Nov 2023 · 1 min read
I'll share more thoughts on OpenAI Dev Day announcements soon, but one huge problem for any developer is LLM API latency. And boy, did OpenAI deliver.
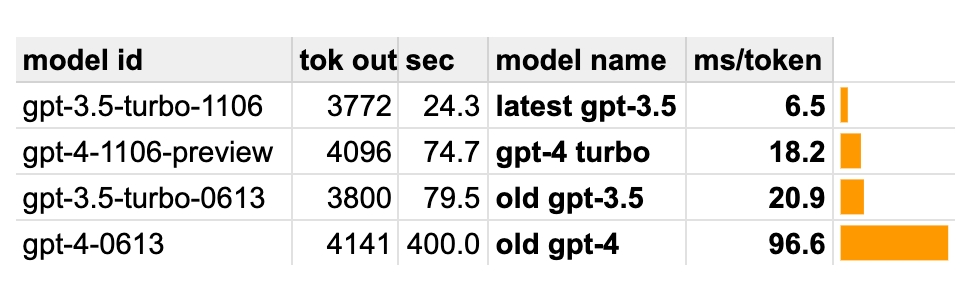
On a quick benchmark I ran:
- gpt-4-1106-preview ("gpt-4-turbo") runs in 18ms/token
- gpt-3.5-turbo-1106 ("the newest version of gpt-3.5") runs in just 6.5ms/token
When you put that into context, it's a wild jump:
- gpt-4-turbo is 5x faster than gpt-4
- gpt-4-turbo is faster than gpt-3.5 used to be
- gpt-3.5 is now 3x faster than June version of gpt-3.5
A bit more detail on the results:
I'll try to get a proper benchmark up soon, possibly using Anyscale's new llmperf tool.