
stream
GPT-3.5 and GPT-4 response times
Some of the LLM apps we've been experimenting with have been extremely slow, so we asked ourselves: what do GPT APIs' response times depend on?
It turns out that response time mostly depends on the number of output tokens generated by the model. Why? Because LLM latency is linear in output token count. But the theory isn't crucial here: we can directly measure how much latency each token adds by calling LLMs with different max_tokens values.
So that's exactly what I did. I tested GPT-3.5 and GPT-4 on both Azure and OpenAI. For comparison to Open LLMs, I also tested Llama-2 models running on Anyscale Endpoints.
Here are the results. Each pane is a model/deployment combination; the horizontal axis is output token count, vertical axis is total response time, each dot is one measurement, and the trend line is the best linear fit to these measurements.
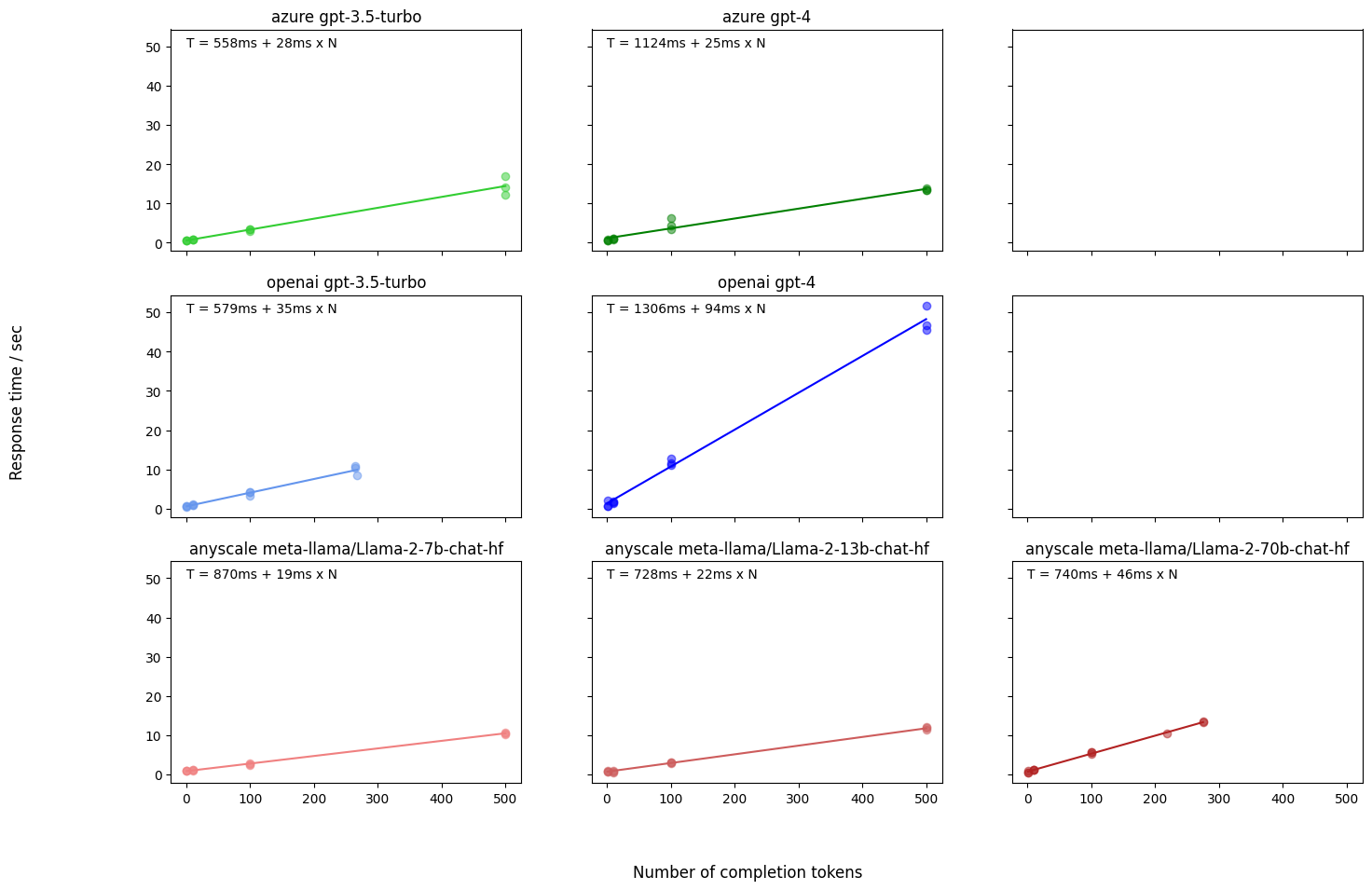
- OpenAI GPT-3.5: 35ms per generated token.
- Azure GPT-3.5: 28ms per generated token.
- OpenAI GPT-4: 94ms per generated token.
- Anyscale Llama-2-7B: 19ms per generated token.
- Anyscale Llama-2-70B: 46ms per generated token.
Azure is 20% faster for the exact same GPT-3.5 model! And within the OpenAI API, GPT-4 is almost three times slower than GPT-3.5. The smallest Llama-2 model is only 2.5 times faster than the biggest one, even though the difference in parameters is 10x.
You can use these values to estimate the response time to any call, as long as you know how large the output will be. For a request to Azure GPT-3.5 with 600 output tokens, the latency will be roughly 28ms/token x 600 tokens = 16.8 seconds.
Or if you want to stay under a particular response time limit, you can figure out your output token budget. If you are using OpenAI GPT-4 and want responses to always be under 5 seconds, you need to make sure outputs stay under 5 seconds / 0.094 sec/token = 53.2 tokens. (Optionally, enforce this via the max_tokens parameter.)
These numbers are bound to change over time as providers optimize their models and deployments. For example, between May and August OpenAI was able to make their GPT-4 more than twice as fast per token! However, I expect these coefficients to change over the course of months, not days, so developers can consider them roughly constant within any given month.
Latency may also vary with total load and other factors -- it's hard to tell without knowing details about the deployments. However, the key thing to remember is this: to make GPT API responses faster, generate as few tokens as possible.
If you want to dive deeper, see my post on how to make your GPT API calls faster.
A caveat: these numbers will change over time as providers optimize their models and deployments -- e.g. between May and August OpenAI was able to make their GPT-4 more than twice as fast per token! However, I expect them to change over the course of months, not days, so from a user perspective you can consider them constant, and maybe review your model choice every now and then.
Experiment details
Here's how I ran my experiments.
- Made an API call for each value of
max_tokens, per model and provider. (Three repetitions for each combination to understand variance). - Fit a linear regression model to the outputs, including intercept.
- Reported the coefficient as "latency per token".
And some more boring details:
- Experiments were run on 09 August 2023.
- Network: 500Mbit in Estonia (at these scales network latency is anyway a very small part of the wait).
- For OpenAI, I used my NFTPort account.
- For Azure, I used US-East endpoints.
- For Anyscale, I used my personal account.