
Tesla's data engine: the road to full self-driving
I've driven a Tesla only once but looking at Karpathy's recent presentation at the CVPR conference, soon no human will. I think Tesla's unique data engine is what will get them there.
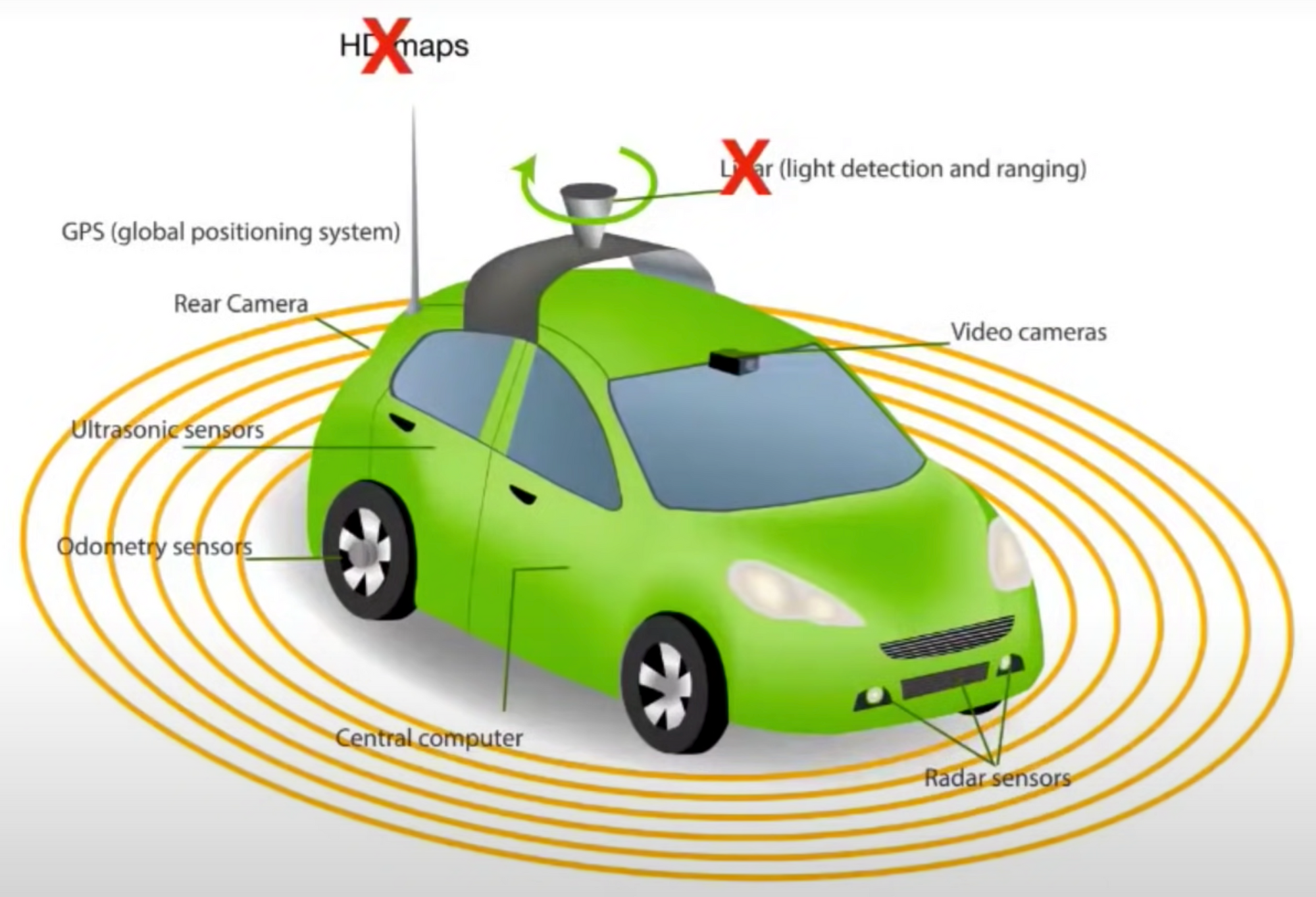
In their self-driving stack, Tesla has always been betting on cameras and radar. This contrasts with Waymo's bet on more expensive lidar and pre-mapping. It turns out vision alone is so much better than radar that the latter is not even worth including as an input signal. Musk is putting his money where Karpathy's team is: new Teslas are now shipped without forward-facing radar hardware.
This is amazing as it stands. While cameras give a rich view of the surroundings, they are limited in range and cannot see behind/under/around obstacles. An unassisted human driver relies only on vision, and Tesla's removal of radar further shows the power of neural networks.
But more amazing to me is how they achieved it: getting a really expensive dataset at a huge discount. The dataset has to be a) large, b) clean, and c) diverse, as Karpathy explains. Getting a large dataset is straightforward. A clean one takes work. But diversity at scale is tough.
99.9% of driving seconds are straightforward situations that the self-driving system is already good at. There is a needle in the haystack: if you know which clips contain the most interesting edge cases, you can easily label them. But you don't know where to look, so you have to sift manually watch 1,000 clips to get one interesting label.
Getting long-tail labels is a problem in building any AI system. Doing so cheaply is even harder. Here are some key components of Tesla's approach.
- Offline auto-labeling with compute-intense models -- much bigger ones that would be feasible to use in the car real-time.
- Using the future to label the past -- e.g., when a car just cut in front of you, you can label it as "about to change lane" a few seconds earlier.
- Label time-consistency: a car detection should not jump around the frame every few milliseconds.
- Using extra sensors (radar!) to create labels, even if you don't have that sensor available in production.
- Hand-tuned triggers that collect a clip when something is unexpected, e.g., when the self-driving system thinks the car in front is slamming the brakes, but the human driver is not braking (an implicit label from the owner/driver of the particular vehicle!).
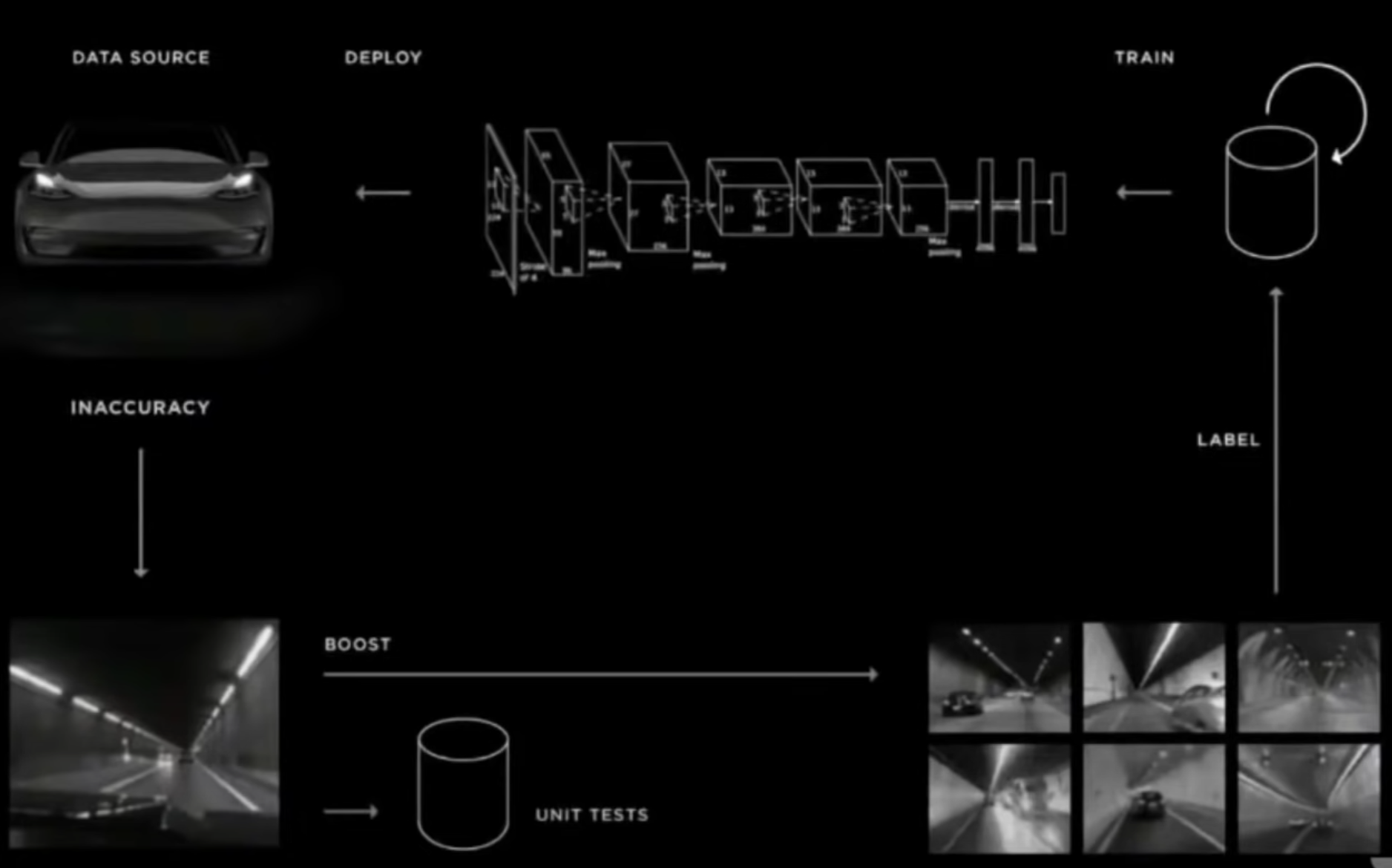
All the tricks above are cleverly using side information to get labels. The resulting dataset is huge: 10 million labeled driving seconds. Funnily enough, the self-driving team at Starship independently arrived at many of the same approaches to reduce the human work needed to discover and label interesting situations.
There are companies trying to build products for this. Scale, a titan in data labeling, has a newish product called Nucleus. Aquarium Learning is a YC-backed startup building a kind of dataset development software (in Software 2.0, data is the code!). But in 2021, it still takes lots of in-house engineering to build even a basic data engine, never mind one as good as Tesla's.